Data Dump Process
Description:
Data dump is a process to extract raw data from a database and write it down into a csv file to perform further analysis. It runs daily at morning 6.15 AM. Below are the detail breakdown of working of dump process;
Process Flow:
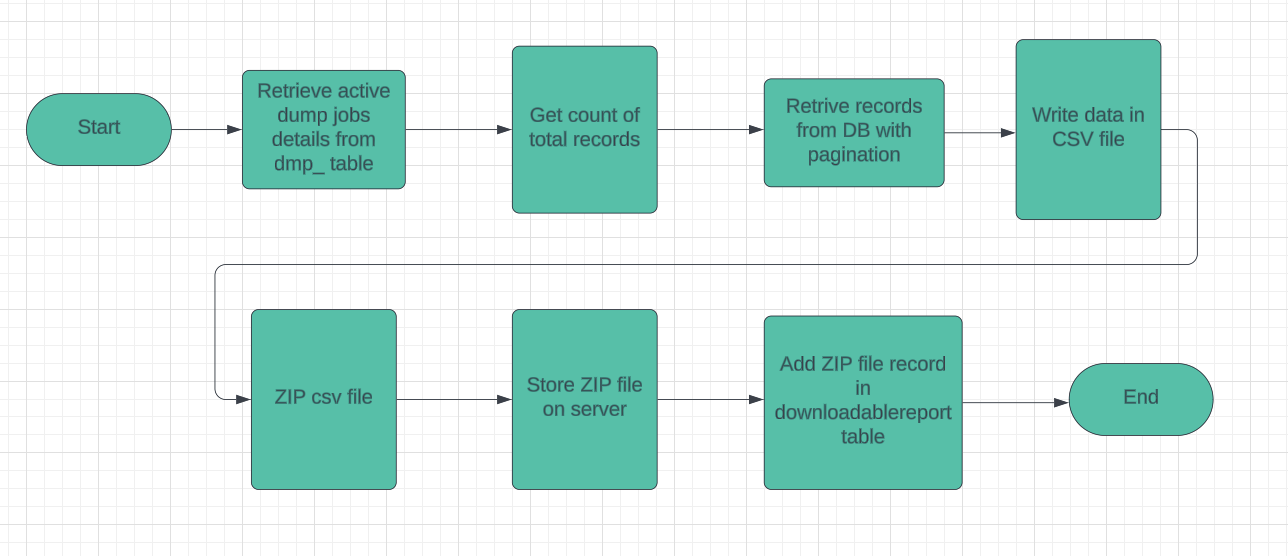
[Check details here](Data Dump Process Detailed.md)